
…to read the Latin & Greek authors in their original is a sublime luxury … I enjoy Homer in his own language infinitely beyond Pope’s translation of him […] I thank on my knees him who directed my early education for having put into my possession this rich source of delight: and I would not exchange it for any thing which I could then have acquired & have not since acquired.
— Thomas Jefferson, Thomas Jefferson to Joseph Priestley, Philadelphia, 27 Jan. 1800
But of the mere facts of history, as commonly accepted, what educated youth of any mental activity does not learn as much as is necessary, if he is simply turned loose into an historical library? What he needs on this, and on most other matters of common information, is not that he should be taught it in boyhood, but that abundance of books should be accessible to him.
The only languages, then, and the only literature, to which I would allow a place in the ordinary curriculum, are those of the Greeks and Romans; and to these I would preserve the position in it which they at present occupy. That position is justified, by the great value, in education, of knowing well some other cultivated language and literature than one’s own, and by the peculiar value of those particular languages and literatures.
— John Stuart Mill, Inaugural Address, 1867.
I’m building a new open source digital library for Ancient Greek using AI.
With the rise of LLMs, we have an opportunity to create new tools for preservation, learning, and engaging with ancient texts that would have taken massive amounts of dedicated and skilled work to produce before.
The tools which pioneered the work of bringing Ancient Greek to the internet can be credited to projects like Perseus Digital Library, Scaife Viewer, and others. Building on top of their work in the age of AI can yield results previously unfeasible.
Thus, there is a unique opportunity to initiate a revival of interest in the works of Antiquity in their original language; to let us hear the authors speak again with their own voices.
To this end I created a set of individual skills, coordinated as a pipeline by a meta-skill text-orchestrator, for creating this database automatically. The goal is: given a single prompt like “Add Plutarch’s Lives”, it will search the web, find the original Greek edition, find public domain English translations, download them, process and clean them, segment them into verses (or create a custom versifiable translation if no extant translation aligns well), create interlinear translations, create Latin transliterations for pronunciation, and create treebank data for each word.
This is still only in the “proof-of-concept” stage, and there are many improvements to make, but it has successfully run through the full pipeline on a few smaller sample texts. Therefore text-orchestrator could be an extremely powerful tool for automating database generation from a single prompt. The data it collects is optimized for learning purposes, and the pipeline ends by generating a database artifact, texts.db, which can be directly imported into the lyceum.quest Ancient Greek reader, which is a companion project to this one. It acts as the interface for the data and is my attempt to bring together all the best aspects of Perseus, Scaife, and other readers online, and improve them where possible.
I also show how I ran Karpathy’s Autoresearch to fine-tune an alignment skill which generates English interlinears for every word of the Greek text. We should be able to use this method to fine-tune any skill in the pipeline, but that is reserved for future work.
Table of Contents
- Why
- Goal
- Limitations
- AI Generated Data
- Agent Optimizations and Workflow
- Desired Data
- Generate, Verify, Optimize Loop
- The Text Orchestrator Skill Pipeline
- Future Directions
- Bottlenecks
- Conclusion
Why
I believe this revival is imperative in a time where technology and culture allow and encourage a distancing from our roots which leaves us further untethered from a deep historical understanding of ourselves and our “story” in the world.
As a result nearly all of the institutions for which learning Greek was once a rite of passage in any serious education are gone, and the curious self-driven student is mostly left with fragmented resources for learning.
Further, the attention economy and modern technology constantly competes with any new learner’s focus.
This deadly trifecta of difficult and fragmented learning resources, with a centuries-long cultural cooling on and de-institutionalization of the classics, and deep distraction-technology integration into our personal lives are deep barriers to overcome, but the rise of LLMs can, I believe, help overcome all three.
I take John Stuart Mill’s view that history is fundamentally interesting in and of itself, and if these three barriers are overcome, students would come flocking back to learn.
Therefore, reviving interest in learning ancient languages mandates lowering those barriers to entry and making the learning process as engaging and as easy to dive into what the student is there to learn as possible.
With LLMs, we can do this.
As Dr. Gregory Crane, founder and head of the Perseus Digital Library, notes:
Now we have multiple Large Language Models (LLMs) that can not only translate but also provide reasonable word-by-word grammatical explanations of any source text. My first goal is to provide my students with enough knowledge so that they can begin to exploit this rich and increasingly complex scaffolding.
[…]
LLMs are slow and frontier models are expensive but, given the money, there is no reason we could not generate literal translations for all Classical Greek and Latin literature.
— Dr. Gregory Crane, Towards corpus-based learning: exercises with Ancient Greek, 2026.
Goal
My primary goal is three-in-one: Create the largest corpus of publicly available online Greek texts with the richest set of accompanying data to allow us to build the most intuitive, engaging, and useful interfaces possible for both learners and experts.
If this is successful, we can expand to other ancient languages, starting with Latin.
I’ve already built the initial version of the interface at lyceum.quest. See the announcement post for the dashboard here.
The proof-of-concept has been validated in showcasing a taste of what’s possible now and is already one of the most feature-rich interfaces available. It aggregates much of the freely-available data online. It makes available side-by-side Greek-English translations with the Greek fully parsed, such that each word of Greek text becomes interactive. A user can click on a word to see a popup containing definitions from each major Greek database (Perseus, Logeion, and LSJ), see morphology and grammar data, and even see an AI-generated contextual meaning. It also has numerous display enrichment options like color highlighting for inflections and grammar, and an Anki-style spaced repetition deck for memorizing words from a reader’s chosen texts.
We can, however, do so much more.
For example, what I personally felt was missing most from my own learning were Hamilton)-style word-by-word interlinear translations, which are rare to find online, as that would fill a primary gap for me when learning. So I had Claude generate them custom for the Iliad, which was pretty token-heavy and expensive. But the value of having disambiguated word meanings was immediately apparent. Further, it’s extremely important to note that for most Greek texts, interlinear translations have never been done. Even for the Iliad itself, I was unable to find a complete interlinear English translation (Hamilton himself, the champion of this method, only did this for a few books of the Iliad).

In short, it takes a tremendous amount of effort even from expert humans to create interlinear translations, which the world would greatly benefit from having. This is just one example of a real gap here that could benefit greatly from AI.
Limitations
A major goal is to do this for as many texts as possible, starting with the most desired texts like Homer, Plutarch, The Gospels, or Meditations. But I was generating these interlinear translations through manual prompting, with crude trial-and-error experimentation. I eventually learned to feed it “ground truth” data (using Hamilton’s Iliad interlinear as a sample) so that it could develop an alignment skill from which it would produce Hamilton-like interlinear translations for a given text. I was able to achieve moderate success with this but still found the method too manual, ad-hoc, and error-prone, and translations would not always disambiguate the word correctly for the given context.
Two things quickly became clear:
- There was much more we could do than merely interlinear translations.
- My current approach of prompting AI per-translation was expensive and unscalable.
For (1), I realized I wanted more than interlinears. In one reader view, I wanted:
- Full prose translations (as many public domain as I could find)
- Interlinear beneath each word
- Segmented verses, like the Bible (enabling side-by-side views)
- Transliterations (the Latin rendering for pronunciation help)
- Treebanks containing grammar, inflection, and other morphology data for each word (ideally color coded for easier sight-recognition)
This way, information could be progressively revealed to the reader as it suits them. They can try to learn each word one at a time, learn how it fits within the phrase or sentence, then learn how that sentence fits within the greater narrative. This level of granularity exists at the word level.
This way, the text can truly “come alive” as each word now represents a rich treasure trove of data that a reader can dig into at their preference and to their taste.
So a single Greek text can go from this:
To this:
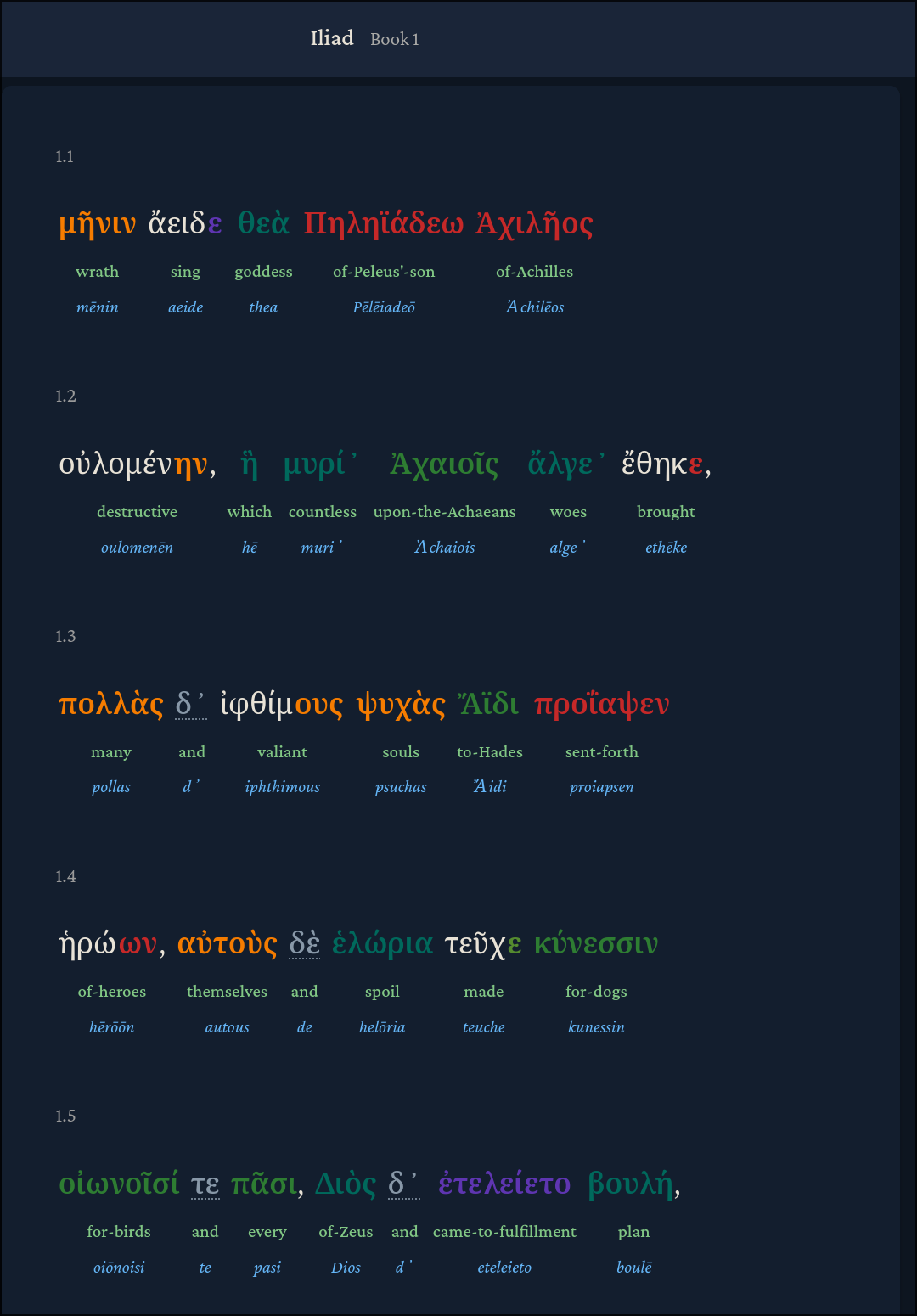
These are just a sample of the things we can do with static, one-time LLM use. We could also add interactive AI chat elements like highlighting and asking about a passage, like ancientgreek.jean.land does, for example. Or a chat just to talk about a specific work or ask general questions.
Eventually, we could even use AI speech-to-text (STT) and text-to-speech (TTS) features to help students learn and grade their pronunciation, or read passages to them.
AI Generated Data
For now, we will focus on what can be done up-front with AI. The tradeoff we are making at present is that the high costs of doing this work are all in the initial phase. Adding in dynamic AI features can come later. A good static data set for translations/transliterations etc. only needs to be done once and is then available forever.
Some, like ancientgreek.jean.land, have taken the approach of using AI to quickly generate translations on the fly, which is a great novel feature. But this won’t scale and should be long-term unnecessary. We need not spend tokens on any of the work required here any more than is necessary to produce a correct result. Therefore, what’s really needed is a large token budget to:
- Refine a process for generating the translations
- Create translations using it
And then a budget for human Greek experts to:
- Manually audit and correct the data produced by the process itself
- Optimize ground-truth “holdout” data used by the agents to evaluate the quality of their work by (and automate improvements)
Agent Optimizations and Workflow
LLMs have recently passed a capability threshold in which many programmers find themselves no longer writing code, but exclusively prompting instead. This has led to massive debates on the true efficacy of LLMs: whether the code they produce is truly high-quality, functional, and maintainable, or “slop” masquerading under a flashy veneer. There is significant skepticism in the Classics community as well.
Despite valid misgivings, it appears that with the right workflows AI can produce surprisingly accurate results, which can then be refined by a human expert.
So if AI can translate accurately enough, this turns the problem from one of translation generation to one of validation, and the human cognitive load for validating work is orders of magnitude easier than the act of creating it.
This means we can, perhaps, for the first time in history, have a hope of creating a unified corpus rich interlinears, morphology data, versifications, and more to provide progressively enhanced experiences when engaging with ancient texts, all-in-one, as opposed to the fragmented efforts which exist today.
That said, the current state of the art appears to involve the heavy use of markdown files like SKILL.md and AGENTS.md along with intelligent context management (context being the primary scarce resource for agents). I’ve attempted to use best practices where possible to build a scalable pipeline for Lyceum which can take a simple query like “Add Plutarch’s Lives” and end with a rich set of data which includes the texts, translations, generated interlinear, etc. which are ready to import into the reader.
Desired Data
As I was working through this it soon became clear that we may be able to automate the following:
- Interlinear translation
- Latin transliteration
- New Testament-like verse segmentation of Greek/English for phrase-level learning
- Custom “versified” translation if no English translation aligns well (ex. Homer translations are rarely direct)
- Treebanks
Each of these would have been extremely time-intensive pre-AI, but following a Generate-Verify-Optimize loop (below), this could become a far more feasible task of auditing and verification rather than generation from scratch.
Generate, Verify, Optimize Loop
Using agent skills, if we apply an approach of Generate-Verify-Optimize feedback looping, we can refine texts through a combination of agent-based methods like Karpathy’s Autoresearch and human feedback loops. For any skill we have which generates data, like /skill:create-interlinear, we craft human-expert curated data we can verify against from which the agent can optimize itself.
We save this verification “holdout” data to be used only for evaluation against the LLM’s results at the end of the process, so as not to bias it.
After comparing the generated data against the holdout data, we can see the error rate. There is some ambiguity here, as Greek word-level translations can have multiple correct meanings, even given the same passage or context.
For example, the opening word of the Iliad, μηνιν, could mean “wrath” or “rage”, and if the holdout data only has “wrath”, it could count “rage” as incorrect. Of course, over time the holdout data can be refined to account for multiple correct answers, but the primary downside is negligible as it just means we’re forcing the AI to conform to a specific style.
After verification, based on how effective it was, we can optimize the skill, either by hand or using tools such as Autoresearch.
Human verification is mandatory, but using Autoresearch to improve the skill can be very helpful and save a lot of time skill debugging. Autoresearch can be extremely effective at optimizing to hit a benchmark, but if the holdout data isn’t sufficiently accurate, or diversified enough to be representative of our generic goal of being able to work with any Greek text, we could be optimizing for the wrong solution. Of course, multiple skills could be optimized. This is where human judgement should intervene and manually inspect both the skill to ensure the wording accurately captures our goals, and, more importantly, the holdout data to make sure we’re optimizing the right target.
The current recommended path is probably something like:
- Human prompts AI to create generation skill to achieve a goal (i.e. “Generate interlinears for a given Greek text”).
- Human reads and refines the generated skill.
- Human creates holdout data or runs the skill once to see what sort of data it generates.
- Human inspects holdout data and refines it to their exact requirements.
- Begin AI Generate-Verify-Optimize loop with Autoresearch, which will: a. Generate the data by invoking the skill in a subagent. b. Verify the skill’s efficacy. c. Optimize the skill by tweaking in response to failures.
- Stop after N predetermined rounds or until the correctness threshold is met (e.g. 95% translation match against holdout data).
- Human re-reads generated skill to ensure no unexpected overfitting.
- Re-run Autoresearch if desired threshold isn’t met.
Personally, I don’t see a problem with having the AI generate a skill initially: it’s often trivial for AI to lookup SKILL.md best practices and implement them better and faster than a human can. But since the temptation to “let the AI handle it” is strong due to the experience of waiting around for it to complete its tasks, the human-in-the-loop should take extra caution to ensure it’s behaving as expected, truly matching against the holdout as it claims to be, and passing against large and diverse sets of holdout data that accurately capture the breadth of the desired output.
The Text Orchestrator Skill Pipeline
The text-orchestrator pipeline is a “set of skills” skill. Its goal is to take a simple prompt like “Add Plutarch’s Lives” and end with an output/texts directory containing a set of .json files and a query-able database texts.db which contains all the data listed in our desired list above. This texts.db is the same one that lyceum.quest uses.
As subsequent texts are added via text-orchestrator, the skill is instructed to update, not overwrite, texts.db.
text-orchestrator spawns subagents to orchestrate a 10 stage process from a kickoff prompt:
| Stage | Name | Script | Description | Key Artifacts |
|---|---|---|---|---|
| 0 | Intake | text_pipeline_intake.go |
Resolve the requested work, choose add/apply mode, and create or refresh the workspace. | manifest.json, state.json, provenance.md, replay/stage-history.json |
| 1 | Source Discovery | text_pipeline_source_hunt.go |
Find, rank, and record Greek/English/auxiliary source candidates with provenance and license notes. | sources/greek_candidates.json, sources/english_candidates.json, sources/auxiliary_resources.json, sources/source-recommendations.md |
| 2 | Extraction | text_pipeline_source_extract.go |
Acquire approved sources, extract parseable text, preserve raw downloads alongside extracted output. | raw/*, extracted/greek.txt, extracted/english.txt, qa/extraction-report.md |
| 3 | Cleaning | text_pipeline_text_cleaning.go |
Remove contamination, normalize Unicode, produce trustworthy clean text with an auditable report. | clean/greek.txt, clean/english.txt, clean/cleaning_results.json, qa/cleaning-report.md |
| 4 | Segmentation | text_pipeline_segmentation.go |
Choose the canonical reference system and segment Greek into stable structural units. | structured/greek.json, structured/greek.txt, structured/reference-inventory.json, qa/segmentation-report.md |
| 5 | Witness Collection | text_pipeline_translation_witness.go |
Gather, normalize, and catalog PD English translations as reference material. | witnesses/catalog.json, witnesses/<name>.txt, witnesses/README.md, qa/witness-report.md |
| 6a | Translation Synthesis ★ | generate_translation.py |
Generate verse-aligned English from Greek, adversarially reviewed against PD witnesses. | versification/chapter_*.json |
| 6b | Versification | text_pipeline_versify.go |
Validate 1:1 alignment of generated translation with Greek; prepare verse-aligned edition for import. | versification/english_versified.json, versification/english_edition.json, versification/alignment.json, versification/metadata.json, qa/versification-report.md |
| 7 | Transliteration | text_pipeline_transliteration.go |
Generate deterministic romanized transliteration for every Greek token. | interlinear/transliteration.json, qa/transliteration-report.md |
| 8 | Interlinear/Treebank ★ | text_pipeline_treebank.go, text_pipeline_alignment.go |
Import/generate treebank data and build candidate word-level interlinear glosses. | interlinear/candidate-alignment.json, interlinear/chapter_*_llm.json, interlinear/morphology-constraints.json, interlinear/treebank-constraints.json, qa/treebank-report.md, qa/alignment-report.md |
| 9 | Reader QA | text_pipeline_reader_reliability.go |
Audit whether the text works in the reader — verify display modes, detect silent blanks. | qa/reader-reliability-report.md, qa/reliability-report.md |
| 10 | Ship | text_pipeline_new_text_ship.go |
Promote approved artifacts into the shipped DB, run import/build, assemble final review pack. | qa/final-review-pack.md, editions/segments in texts.db |
★ = Full LLM judgement required at this step, expensive
Since the stages are sequential, the subagents are spawned for essential context savings. Scripts are also used to make the process deterministic, allowing the LLM to save precious context on making hard-to-script judgement calls, like whether to create a custom translation for versification or use an existing translation that is sufficiently versify-able. The use of scripts also allows us to add tests.
text-orchestrator is a versatile skill which can be used with the following commands:
/text-orchestrator run [work] [--mode add|apply] [--profile <profile>]— Run the full pipeline for a text/text-orchestrator replay [work] --profile <profile>— Replay specific stages on an existing workspace/text-orchestrator resume [work]— Resume an in-progress pipeline from where it stopped/text-orchestrator step [work]— Execute only the next pending stage, then stop/text-orchestrator status [work]— Show pipeline progress and next stage/text-orchestrator abort [work]— Mark the pipeline as blocked and stop
The most important of these is perhaps the replay command, which can replay specific stages of the pipeline at will. A dedicated text-replay skill is also provided which can regenerate data from the already-extracted sources. These skills are important since as we iterate on improving the skills and pipeline, we can run replay to improve on the previous results without having to start from scratch.
I’ve tested the current iteration of the full text-orchestrator pipeline on two small text samples so far:
- The first 5 hexameters of the Iliad
- Aesop’s Fable The Crab and the Fox
The interlinear generation run provides cost tracking when run in API mode (faster and better provenance, but much more expensive than a subscription). In the future this will be added to every stage of the pipeline for complete pipeline cost tracking and provenance. Here are the results of the run for the Iliad:
{
"run_id": "2026-03-24T15:12:41Z-homer-iliad-proem-1-1-5-1",
"text": "homer-iliad-proem-1-1-5",
"book": 1,
"range": "book 1",
"started_at": "2026-03-24T15:12:41Z",
"completed_at": "2026-03-24T15:14:15Z",
"elapsed_seconds": 94.0,
"seconds_per_word": 3.13,
"total_latency_ms": 94006,
"creator_model": "claude-sonnet-4-20250514",
"skeptic_model": "claude-sonnet-4-20250514",
"referee_model": "claude-opus-4-20250514",
"total_words": 30,
"total_batches": 5,
"total_input_tokens": 10187,
"total_output_tokens": 4721,
"total_cost_usd": 0.248784,
"cost_per_word_usd": 0.008293,
"total_challenges": 7,
"challenge_rate": 0.2333,
"failed_call_count": 0,
"model_breakdown": {
"claude-sonnet-4-20250514": {
"calls": 10,
"input_tokens": 6978,
"output_tokens": 2906,
"cost_usd": 0.064524
},
"claude-opus-4-20250514": {
"calls": 5,
"input_tokens": 3209,
"output_tokens": 1815,
"cost_usd": 0.18426
}
},
"benchmark_score": null
}
The interlinear generation is an expensive process as it uses adversarial subagents (Creator, Skeptic, Referee) to debate the best English translation for each word. This is the most LLM-intensive and longest-running part of the pipeline.
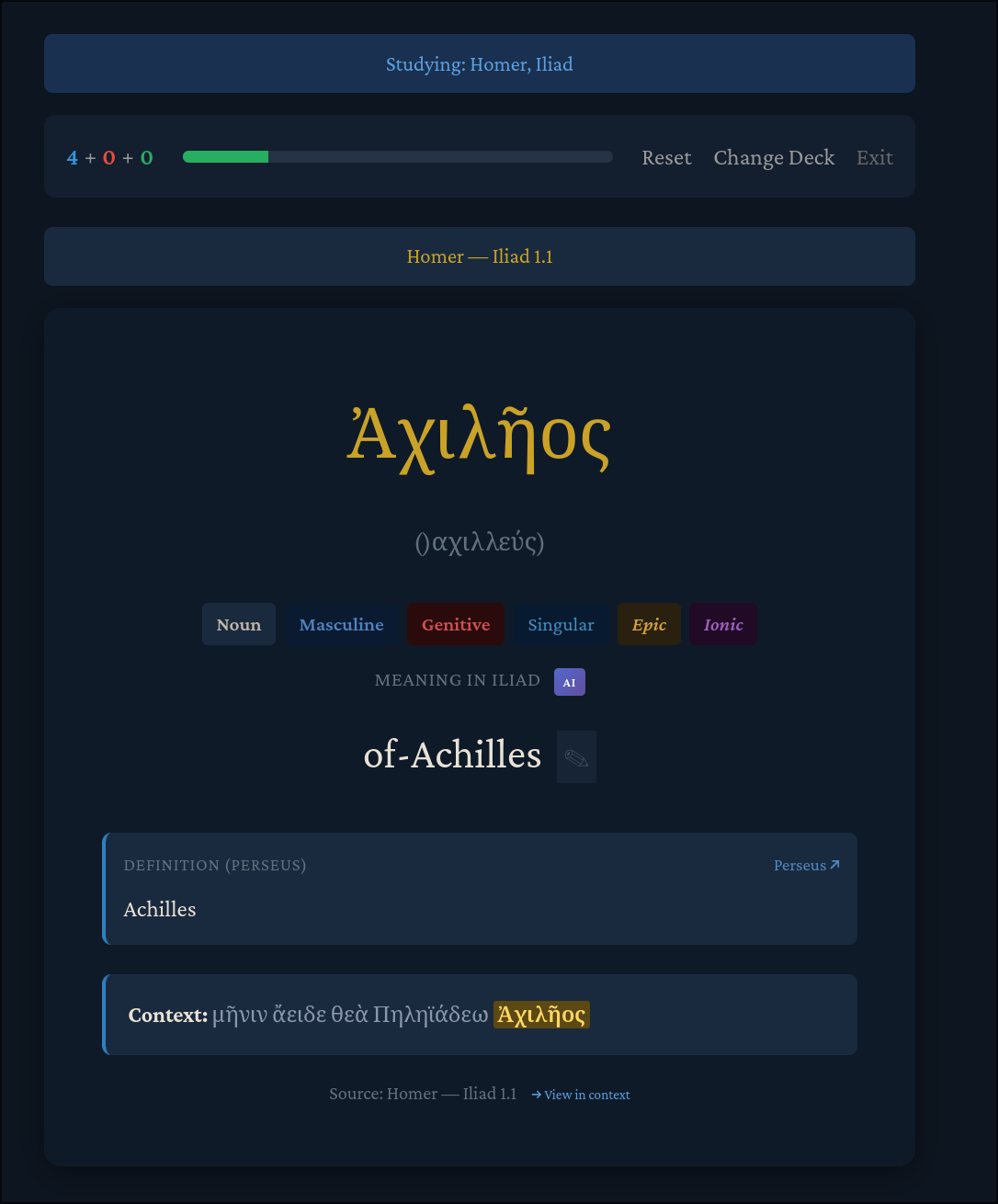
Here are what the results look like after importing texts.db into the reader:
![]()
Here we have lyceum.quest‘s reader enabled with “Transliteration” and “Interlinear” toggled on. This sectioning created by the segmentation skill enables us to learn the Iliad section-by-section by adding each section to a spaced-repetition, Anki-style deck built-in to the reader, enabling progressive, direct learning by using the most scientifically-proven memorization algorithm known.
Future Directions
There are several directions we can go from here:
One of the most obvious things to do is benchmark various models for accuracy. What we need here are Greek experts to create holdout data for each skill, run Autoresearch against it, and measure results, and tweak. My proposal would be to run autoresearch against individual skills, then run autoresearch against the text-orchestration pipeline as a whole (though defining binary acceptance criteria for
text-orchestrationis a bit “fuzzier” than the other skills).As we refine the processes, we can begin to aggregate or generate new types of data. For example, a recent project used AI to successfully transcribe Latin manuscripts never-before uploaded with a 90% accuracy rate. As this improves we will be able to make previously unavailable data available.
There’s no reason if we get the proper funding that we couldn’t have agents running overnight. Imagine, for example, a Hermes agent running
text-orchestratorfor a predetermined set of texts continuously, to be imported into the reader and evaluated at the leisure of experts. Upon reaching an acceptable confidence interval, we can leave it running for a larger subset of texts and human-verify in bulk.As Dr. Crane mentions in the article “Towards corpus-based learning: exercises with Ancient Greek”, we can eventually use AI on the other end of the spectrum: to create custom experiences per-student (or expert!). For example, a user may be able to highlight a piece of text and ask questions about the grammar, or meaning, etc. AI could tailor lessons to each student such that they can immediately engage with the text while focusing on their specific weak-points.
Hand-crafted books can be much more information-dense and educationally useful than exist at present. Currently, the best-in-class is widely regarded as the Loeb Library. But these books only put a Greek translation alongside an English translation. For a beginner, this makes it very difficult to dive into the Greek because it’s very hard to know from reading the English where words, phrases, and sentences correspond in the Greek. Thus these books are limited in their utility to inexperienced readers. We currently have the ability to replicate Loeb naively without any AI assistance and indeed the reader at lyceum.quest does this already for multiple translations, allowing the user to even switch between translations side by side as they see fit, which the Loeb Library can’t do. In web form, this isn’t as much of a problem as a reader can choose their level of granularity. But in book form, choosing which information to include per-word becomes a judgement problem. Still, I personally would love to have Greek-English editions with color-coded word-inflections, grammar hints, and interlinear translations. Perhaps readers can even select which information they want their copy of the book to include when ordering it from the website themselves, like a build your perfect book experience tailored to their preferences as they would in the online reader. In short, we can come a long way in making the Greek originals “come alive” by curating a tradeoff between information density and usefulness in a novel print format.
Lastly, it should be noted that these skills were generated on a NixOS machine, and thus they’re tied to a lot of
nix-specific instructions. We will soon need to generalize these skills to other Linux systems.
Bottlenecks
Some bottlenecks to the project are:
- Expertly hand-crafted ground truth and holdout data. These holdouts should exist across genres (epic, philosophy, history, etc.) and across dialects (Ionic, Attic, Koine, etc.).
- API token funding. Generating these tokens, especially in multi-stage adversarial loops as exist in text-orchestrator, is token-intensive. The tradeoff we’re aiming to make here is high upfront cost for long-term payoff. Rather than suboptimal on-the-fly generation, it is better to find methods which generate a great translation once, with some degree of human-review acceptable.
- Skill development and model optimization. Methods like spawning subagents for each stage, or even adversarial subagents within each stage (i.e. Stage 8), can help improve results. Karpathy’s Autoresearch for automating skill improvement against holdout data will be extremely useful here.
- The models themselves. I’ve only tested this on Claude models (Sonnet/Opus). Benchmarking will likely reveal models optimally suited to different tasks. It should also be noted that the staggering rate of model improvement may render any processes developed to optimize translations irrelevant, and therefore time invested in optimizing the methods should be weighed against acceptable output quality and the knowledge that any methods we develop are likely to have ephemeral use and diminishing returns.
Conclusion
The rise of LLMs has opened a new door to build better educational tools and more comprehensive databases than have ever existed. The opportunities are particularly salient for niche fields ripe for revival. When building resources for ancient Greek in the age of the internet, we were historically constrained by a shrinking cultural interest in the classics and therefore a smaller pool of experts dedicating resources to creating these tools and databases. Now, however, LLMs have reached a point where custom translations, morphology, and other useful data can be generated with a high degree of accuracy, and it is likely that these tools will continue to improve.
With the careful application of frontier models, quality harnesses, and rigorous human expert review, it is now possible to create a unified, comprehensive database of ancient Greek texts and generate useful data from them optimized for learning and researching.
Hallucination is still a major concern, and more work needs to be done to see if we can reliably produce accurate translations at the word, sentence, and paragraph level.
But the results for the tools as they exist speak for themselves, and skew optimistic.
At this point, I’m bottlenecked by time, money, and Greek expertise. I’ve just been using standard Claude and Codex subscriptions to create and test the orchestrations, but with the right resources and team we can do so much more and at an unprecedented scale.
If you like ancient languages, AI, or are simply excited about preserving and expanding our knowledge of history through digital libraries, please consider Joining the Discord, helping audit translations, donating, or spreading the word!
What I’ve covered here only scratches the surface of what’s now possible to improve our digital access to Greek and other ancient languages.