
I learned ancient Greek as I would have learned a living language.
Heinrich Schliemann, the man who rediscovered the lost city of Troy, quoted from The Story of Civilization Vol. II: The Life of Greece
Months ago, after having visited Rome and delving deeper and deeper into ancient history, I decided I couldn’t tolerate translations for the Ancient authors. I felt compelled to read them in their own words. And this meant that I had to learn to read Greek and Latin. I started on that journey with Ancient Greek. I am still a beginner, but I felt strongly that a tool which met my learning needs was missing. So I used Claude to build a website to bridge the gap: https://lyceum.quest
I began with a top recommendation online: Athenaze. It has given me a great foundation, particularly for grammar, but I quickly became frustrated by a few things:
I was learning Greek through a made-up story about an Athenian farmer. It was engaging, but it wasn’t “real” Ancient Greek and it wasn’t a story they wrote, which quickly became demotivating when things got difficult. This isn’t to fault the book, which is great, but I wanted something that put me in direct contact with the texts to make me feel like I was “unlocking” some ancient secret by learning the language.
So much of language learning is memorization, and we have a scientifically proven solution to the long-term memorization problem: spaced-repetition, which I wasn’t using, and which is very difficult to implement without the help of software. The strategy I was using of just haphazardly writing down words over and over was inefficient and exhausting.
Flipping through glossaries/dictionaries is difficult, and every language-learning book will force you to do this by the nature of that format. Each lesson introduced new words, but if I forgot a previous word somewhere I’d have to find which chapter it was in or flip to the dictionary. Since I didn’t know most words at the start of each chapter because my memorization technique was bad, I found myself spending a lot of time flipping pages. This was further complicated by the fact that each word is inflected, which meant the glossary definitions just had to pick one specific form of that word in the definition. This is confusing to a new student as the dictionary definition often just looks like a completely different word. Eventually, I ended up just typing the words I forgot into an LLM to have it tell me what it was, which was far faster. Double-checking with the glossary I found that the LLM was almost always correct.
The answer key to the book wasn’t built in, which seems common practice for Latin/Greek books, likely because they are geared for universities. But for a self-learner, I had the constant sense that I was veering off course with no way to self-correct except to validate my answers via an LLM and online dictionaries. This was also incredibly frustrating.
There are some books that tried to address concern 1, such as Complete Ancient Greek by Gavin Betts and Alan Henry, but they still have to simplify the original for learning purposes and usually do not seem to address 2-4.
I began to search more seriously for ways to just make direct contact with the authors I wanted to read, with some sort of translation to help me engage with the original. After a bit of searching, it seems that the most serious player in this game is the Loeb Library, which produces beautiful little books which have the Greek (or Latin) original on one page alongside a quality translation on the other. As far as I can tell, this is one of the only publishers which even publishes works with original Greek, translation or no translation. I enjoyed these and tried reading side by side, but this too was difficult and fraught with error. The word orders, and sometimes even sentence orders, of the translations are different. While this was a step in the right direction as an aid to learning and made the process much more rewarding, it still felt incomplete to me.
Eventually I discovered the interlinear and/or Hamiltonian) method of teaching these languages and stumbled across his translation of the Iliad, which felt like a breath of fresh air. An interlinear translation is one where the translation of the word is placed directly below its appearance in the original. One problem with this is that word order in Greek can be completely different than in English, making it harder to comprehend. So Hamilton rearranges the words of the original in order to make them have a more natural flow in English.

Stumbling on this, it felt like the obvious solution. Here the text came alive to me in my language. I was engaging directly and immediately with my purpose for learning it. Suddenly learning transformed from something tedious to something fun — learning the language through the ancient texts is giving me the sensation of unlocking an ancient secret. Learning through made up stories designed to teach lessons, by contrast, felt like busywork that was obscuring my true goals. It was based on the idea that the vocabulary, not the grammar, was the primary blocker to learning a language. This method was pretty popular throughout the 19th century and was advocated by John Locke and others (as you can read in the intro to Hamilton’s Iliad above), and is still in use today by seminary students and many of the most popular apps for Latin learning (Legentibus, for example, uses interlinears). This was a solution to problems 1, 3, and 4 above all in one.
So after learning the basics of declensions and verbs from Athenaze, I switched to solving problem 2: memorization. I painstakingly added Hamilton’s cards by hand, word for word, into Anki. It was slow-going, but I found after a couple days I could actually read a sentence or two of the real Iliad!. And with each day, more.
Then, while listening to The Story of Civilization, Vol. II: The Life of Greece by Will Durant, I heard the insane story of Heinrich Schliemann. As an eight-year-old boy, his father read Homer to him, and little Schliemann became so enamored with it that he made a promise to his father that when he grew up he would rediscover the lost city. Around age thirty, a successful merchant, figuring he’d acquired enough wealth to fund his dream, he set out to find Troy. To the disbelief of many a scholar at the time, it appears that he actually did find it!. In a footnote, Durant includes Schliemann’s journal where he describes how he learned the language, which was the final nudge I needed to inspire me to build Lyceum:
“In order to acquire quickly the Greek vocabulary,” Schliemann writes, “I procured a modern Greek translation of Paul at Virginie, and read it through, comparing every word with its equivalent in the French original. When I had finished this task I knew at least one half the Greek words the book contained; and after repeating the operation I knew them all, or nearly so, without having lost a single minute by being obliged to use a dictionary….Of the Greek grammar I learned only the declensions and the verbs, and never lost my precious time in studying its rules; for as I saw that boys, after being troubled and tormented for eight years and more in school with the tedious rules of grammar, can nevertheless none of them write a letter in ancient Greek without making hundreds of atrocious blunders, I thought the method pursued by the schoolmasters must be altogether wrong….I learned ancient Greek as I would have learned a living language.”
Everything about this felt right to me: the learning by doing approach, not wasting time (academic methods seem to assume you want to make the study of the language a science, and expect you to learn it formally better than your native tongue. In short, they do not respect your time), the observation on ineffectual tedium, the focus on learning it as a living language. It doesn’t hurt that this is what Troy’s discoverer advocated and that he also happened to know Russian, French, English, Dutch, Spanish, Portuguese, Italian, Swedish, Polish, Latin, Arabic, and his native German by the end of his life.
I now had enough intuition about what I felt was lacking to build the tool I wanted.
Building the Website
I asked myself if I could build a website with a rich interface for reading and engaging with the original texts that is better than what currently exists. So I started building, with the following goals in mind:
The reading experience should start by at least achieving parity with current resources (Scaife, Loeb). This meant in practice that I needed English translations (multiple preferred, if available). This alone would let us achieve parity with the other viewers.
There are databases which exist to serve different purposes, but they have not been combined into a single intuitive interface. Combine freely-available, scholarly data in one place so that it can be maximally beneficial.
The site should tightly integrate spaced-repetition features into texts of the reader’s choice as a proven effective method for memorization.
Use AI to do useful upfront work that it would take humans a long time to do (e.g. interlinear text generation). Like in Bitcoin, my primary field, proof-of-work is far easier to validate than to generate. As long as we’re up front about the limitations, there’s no reason we can’t use AI to generate initial interlinear texts which are then refined. I will go into more detail about my thoughts on using LLMs to generate interlinear translations and how I did it here in a subsequent post, but suffice it to say, they can achieve better results than you may expect.
I was aiming for something like a cross between the Scaife Reader (which is difficult to use and more overtly academic) and Legentibus (which has proven very successful, but is more paywall-ed, more focused, and does Latin instead of Greek).
Using Claude to build the site I was able to achieve all of these goals for at least a couple texts each, validating the concept. The one exception is that I need some mechanism and/or scholarly review to validate and correct mistakes in the interlinear texts. Thankfully, these can easily be compared in-site with the scholarly sourced definitions from LSJ, Perseus, and Logeion short definitions at any time for the time being.
Tour of the Site
The homepage gives you an overview of the primary features.
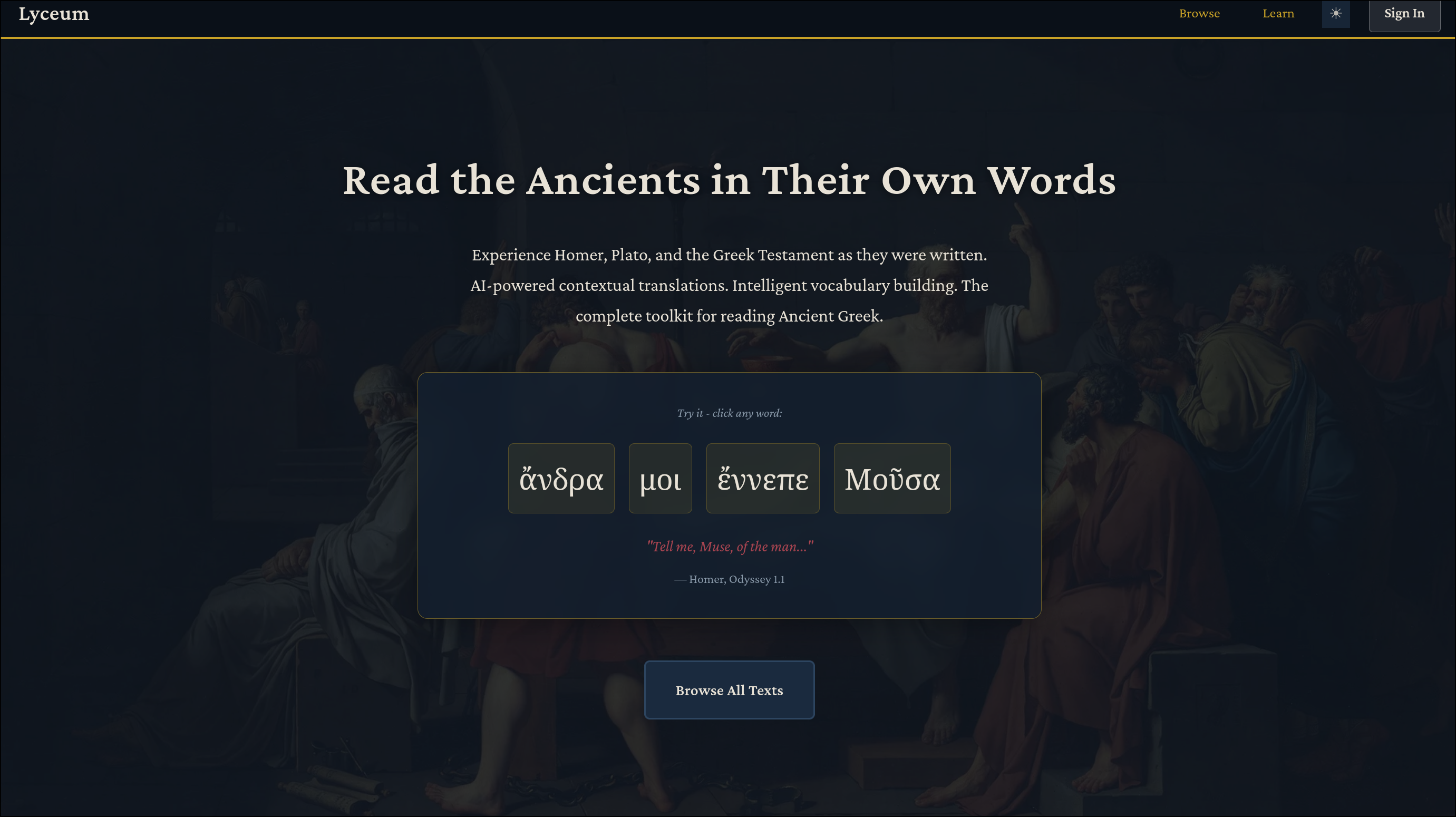
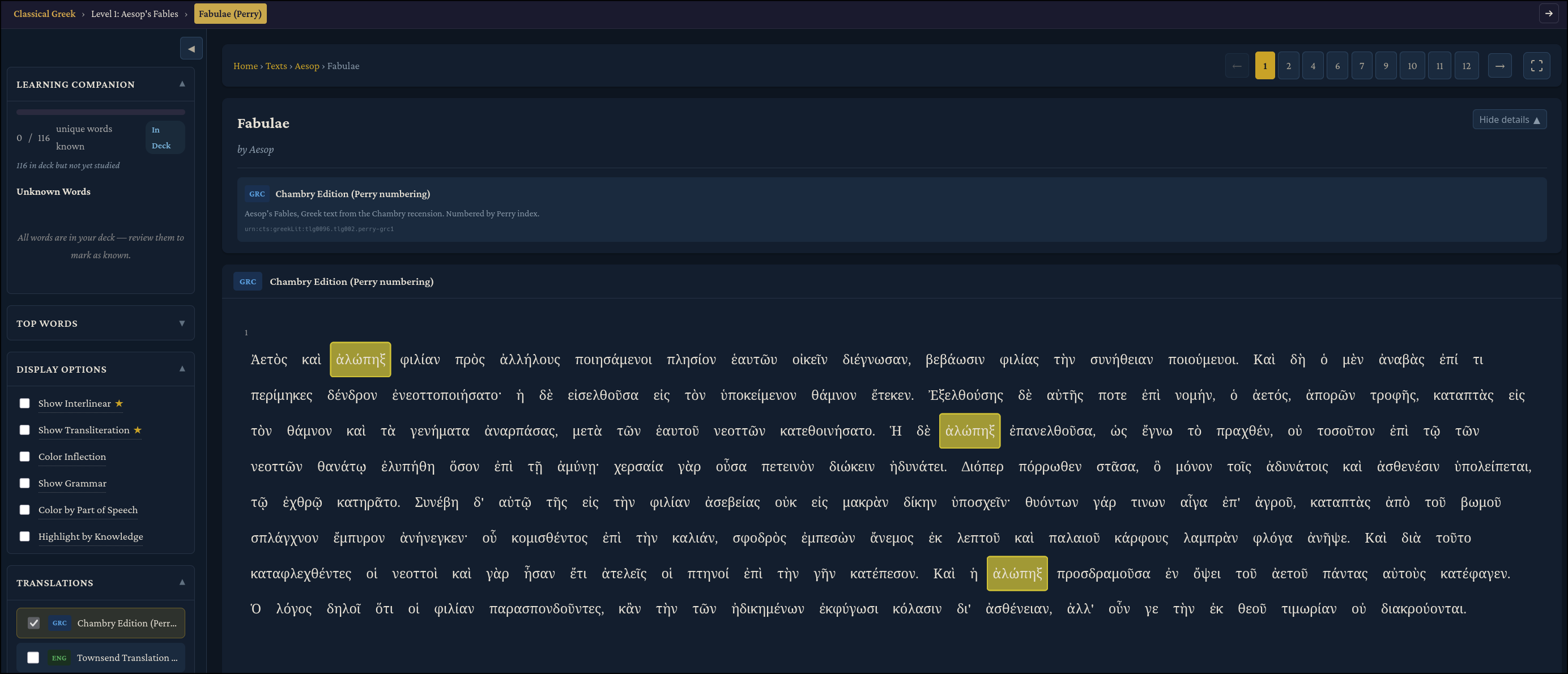
Clicking “Browse All Texts” will take you to the /texts page, where you can search for texts by author or title, similar to Scaife Viewer:
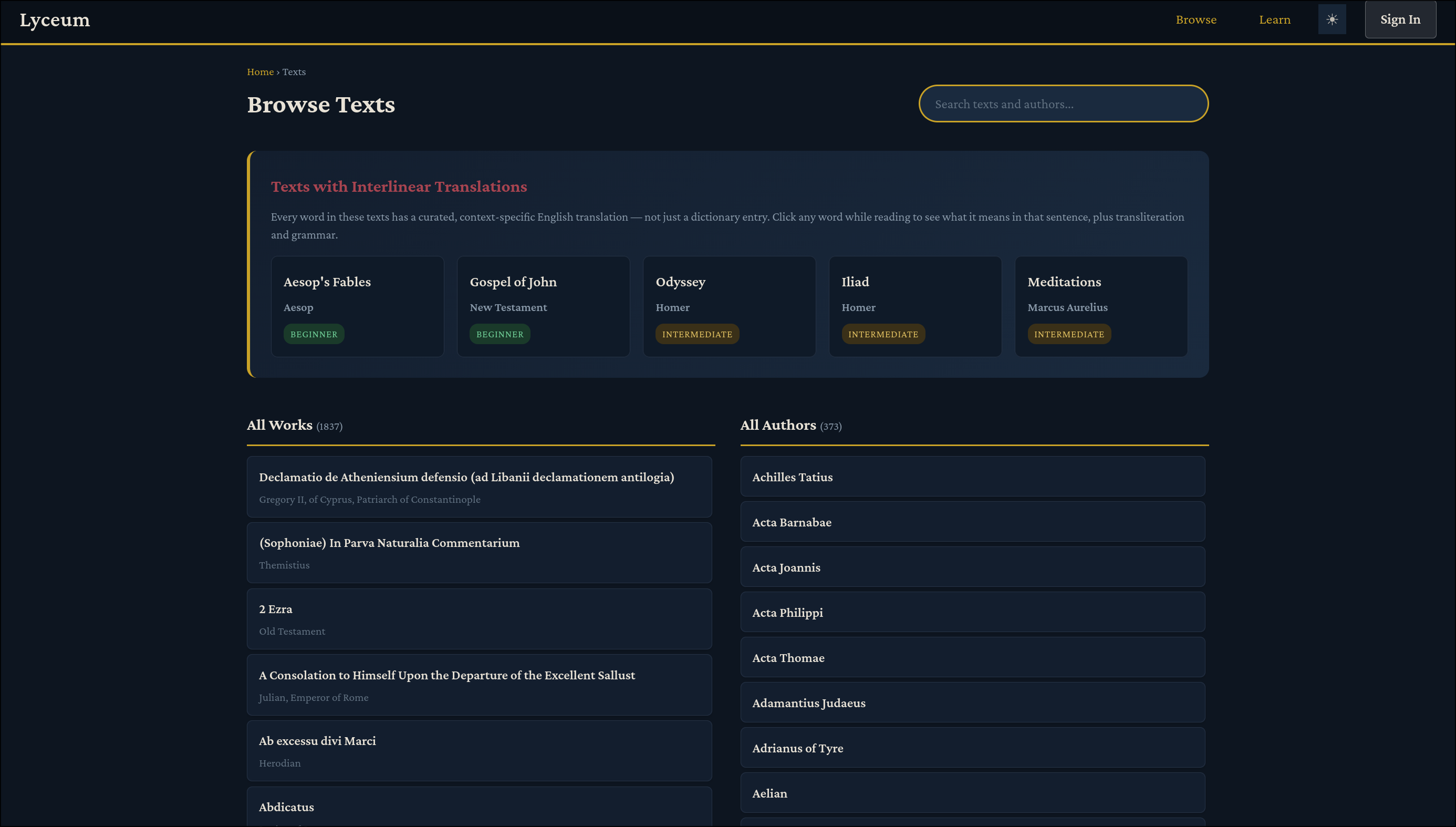
The corpus spans 373 authors and 1,837 works across all sources. Many of these will only contain the original Greek text with no translation for the time being, although I would love to fix that over time. The five texts at the top (Aesop’s Fables, Gospel of John, Odyssey, Iliad, and Meditations) have been given special attention. These texts have interlinear translations and transliterations, and were what was primarily used for building and testing the site. If we click on one, we can see the reader view:
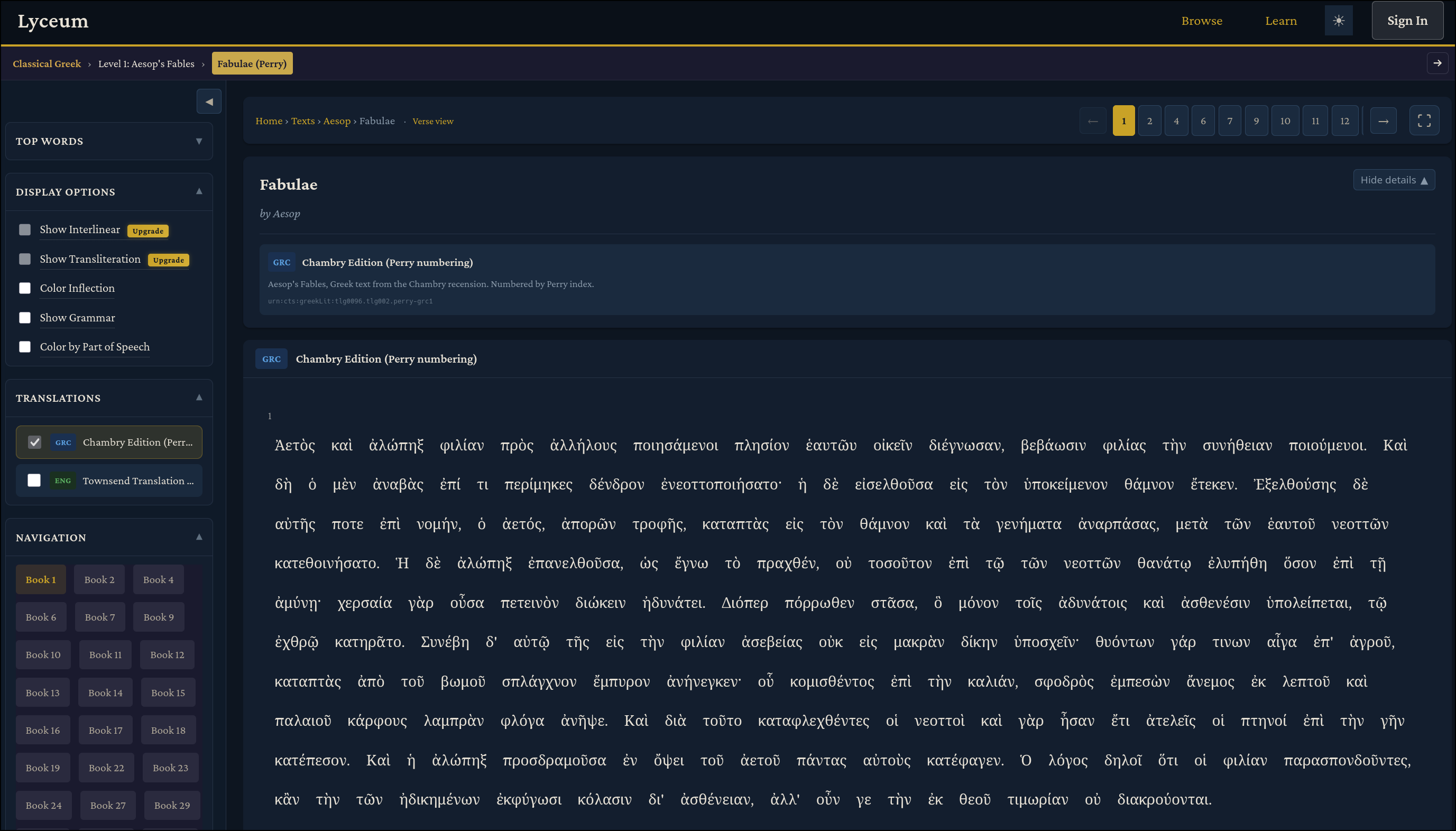
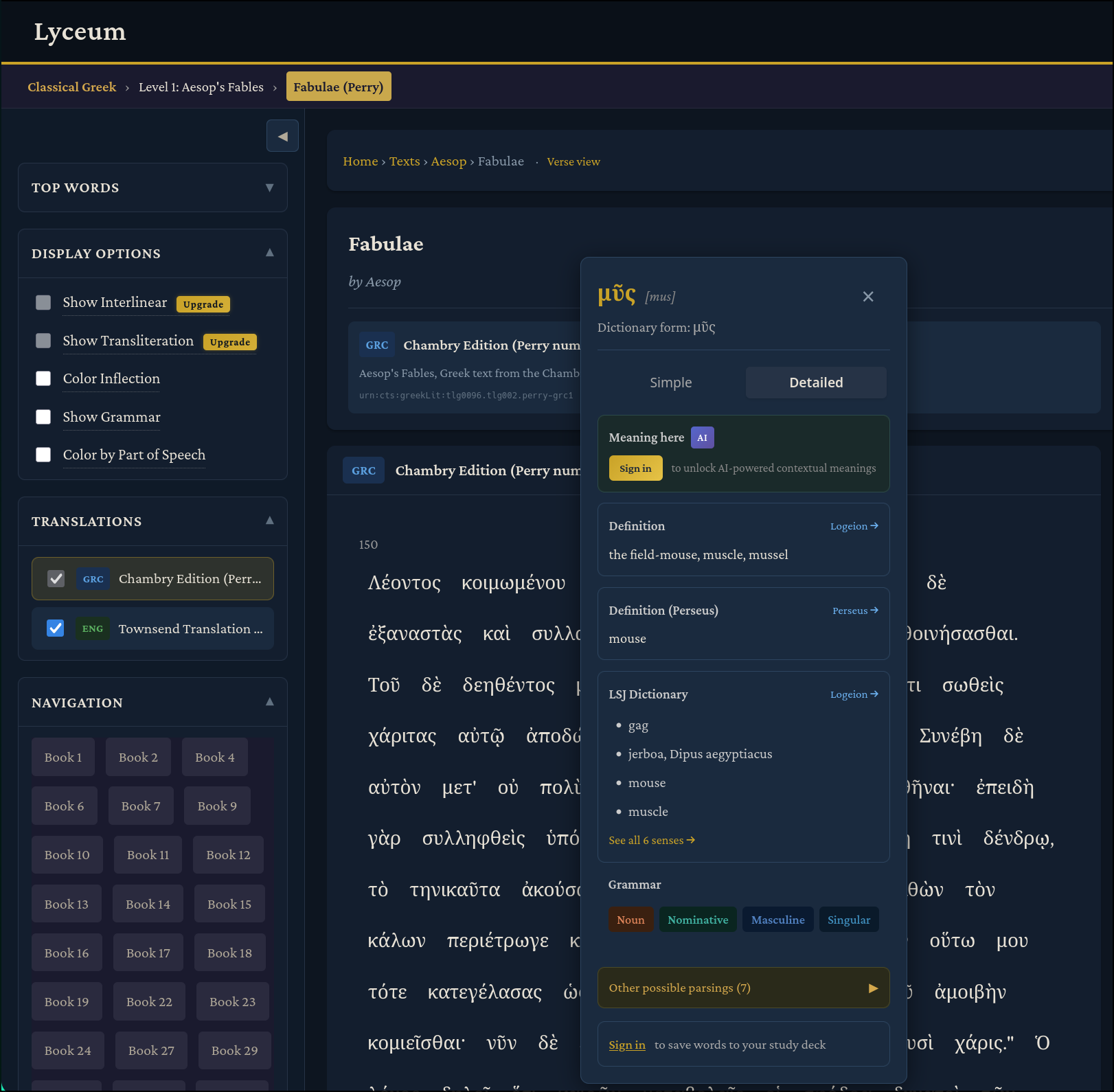
There’s a lot to unpack here. On the “Display Options” card, we have checkboxes which we can use to add morphology information (sourced from Perseus) to each word to help with our understanding of the grammar. For example, there is a “Color by Part of Speech”, “Color Inflection”, and “Show Inflection” option. For each word, there is a popup you can click on to see that word’s definition from various sources (Logeion, Perseus, and LSJ), and grammar. You can also see multiple translations side by side with the original Greek when they are available. Any of these options can be combined to your reading taste. As far as I’m aware, there is currently no Ancient Greek resource which combines dictionary definitions, grammar/morphology, and side by side translations for free.
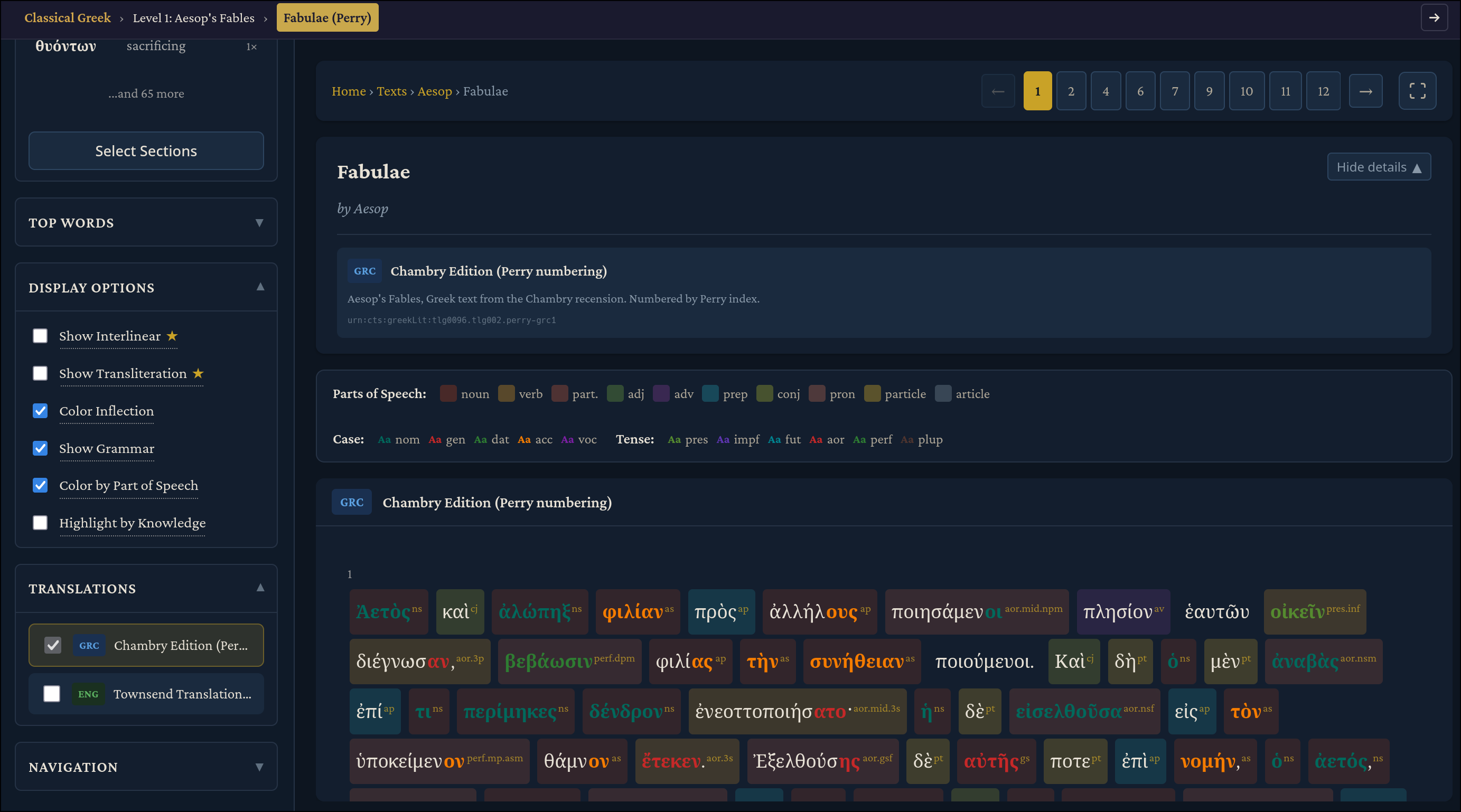
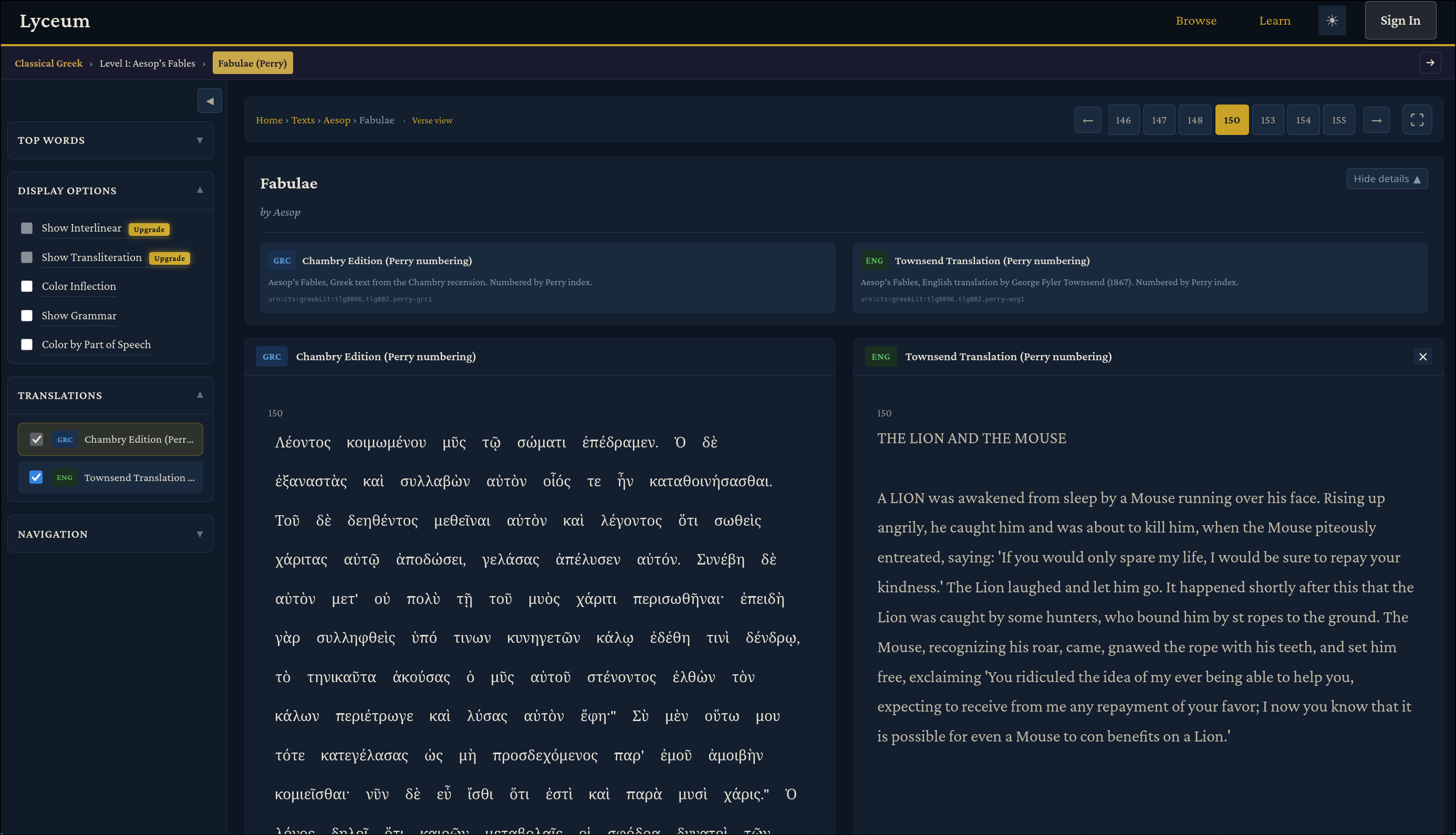
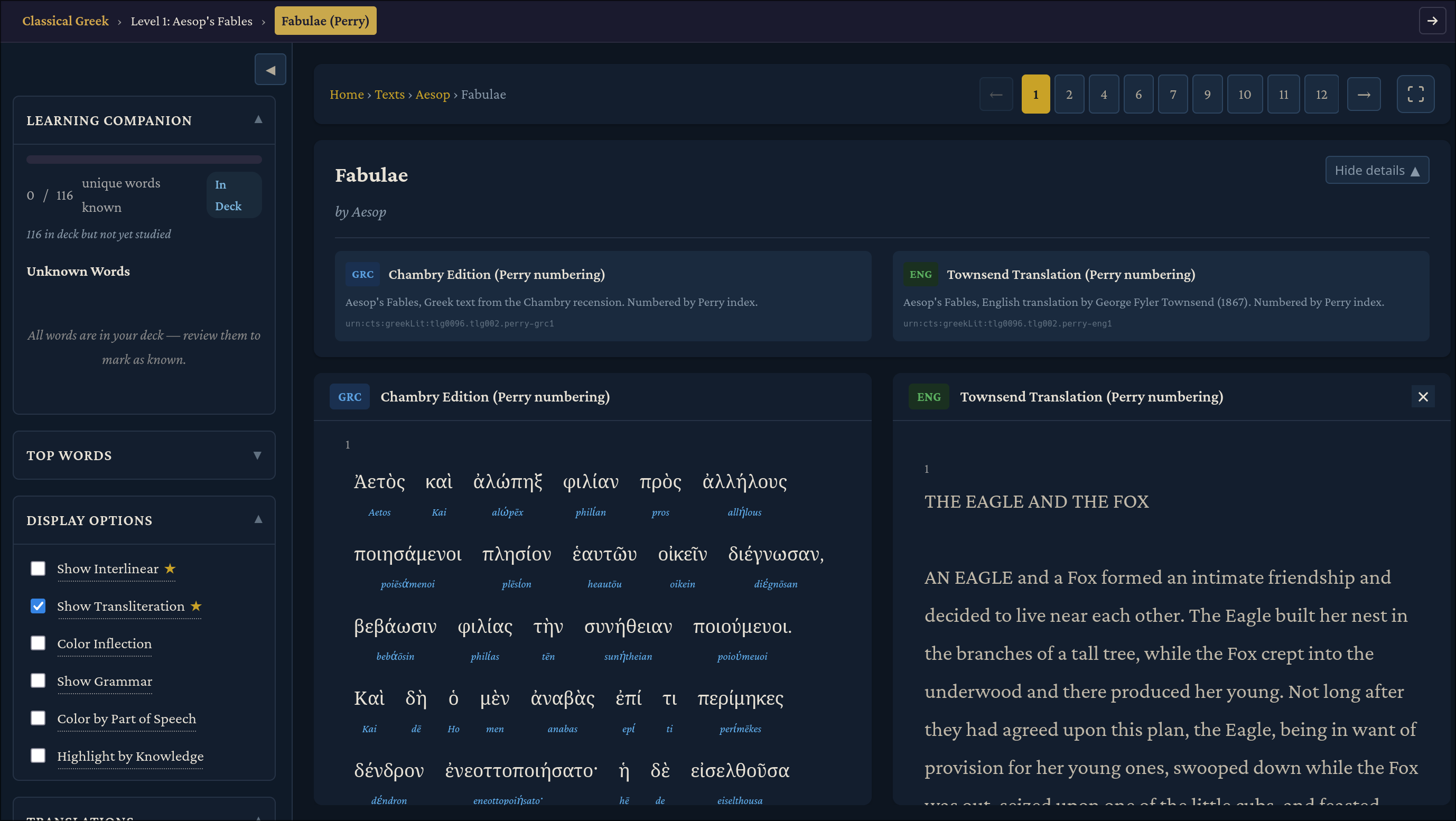
For paid users, the page gets more interesting and useful. Two new checkboxes unlock in “Display Options”: “Show Interlinear” and “Show Transliteration” both generated by Claude. Transliterations are useful to show the Greek characters in Latin text, and thus help beginners to memorize the pronunciation of the Greek characters:
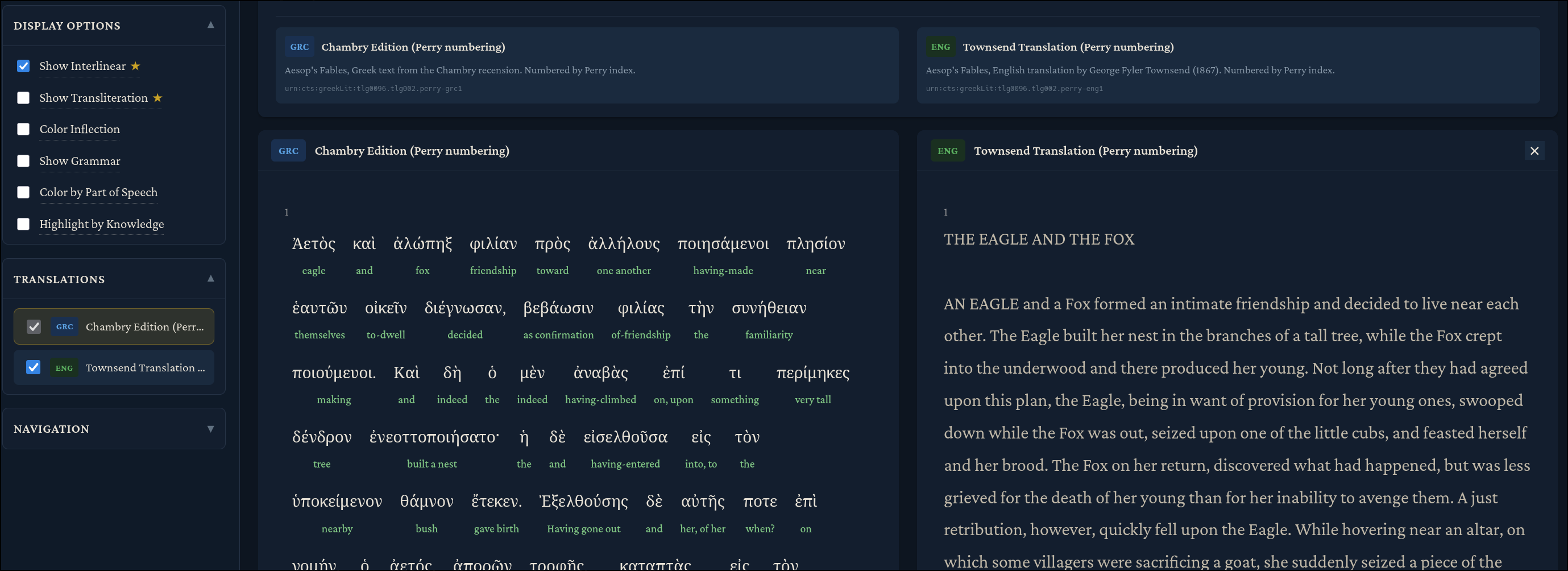
Interlinear texts, as discussed earlier, give you direct word-by-word translations in context, so that you are no longer left guessing which of the many Perseus/LSJ definitions apply in the context of the book you are reading.
Because these are LLM-generated and not scholarly-reviewed translations, you should compare them against their Logeion/Perseus/LSJ counterparts to be certain, but I have found they are usually accurate for these curated texts. You can compare them easily via the popup:
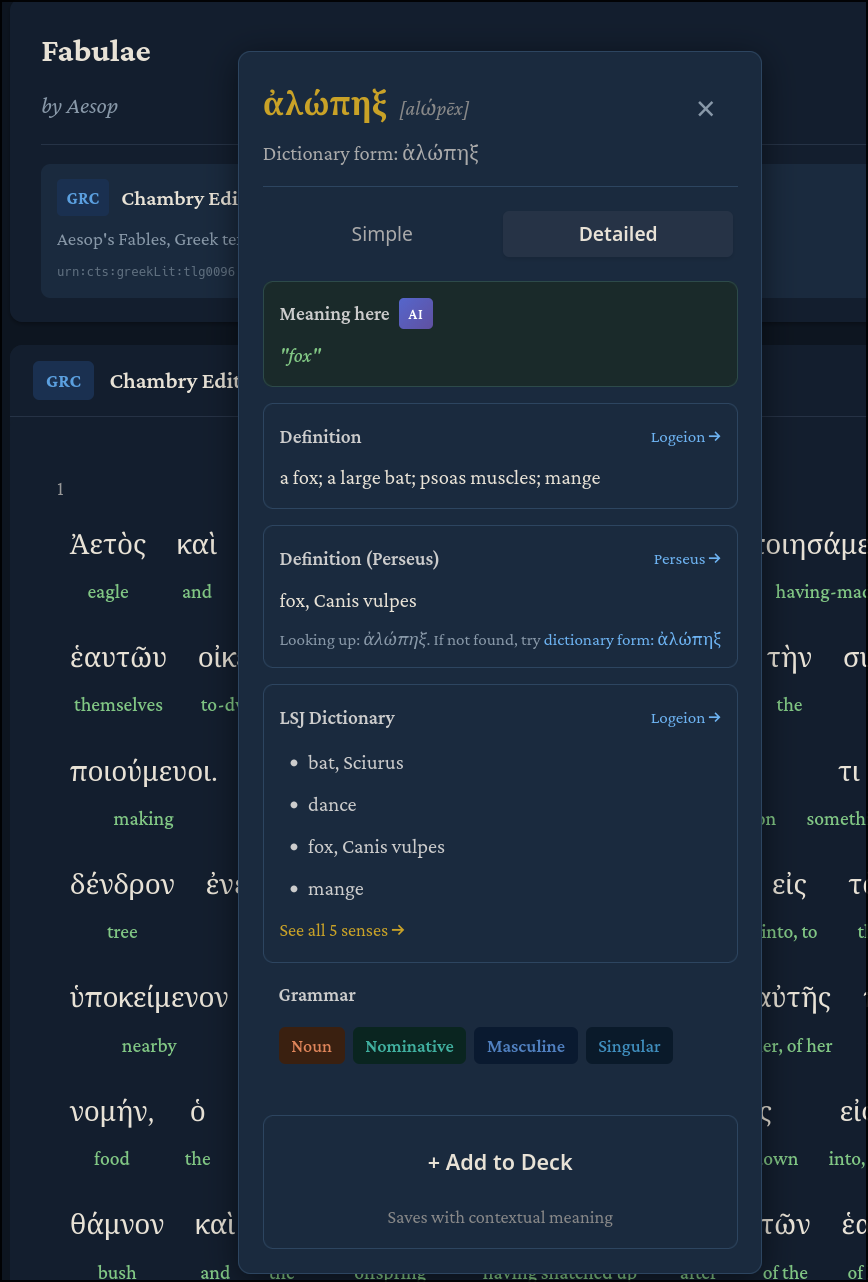
I am working on ways to better ensure/enhance the accuracy of these AI-generated interlinears, but in the meantime, this built-in cross-validation with the official scholarly sources should suffice.
These interlinear translations, combined with official translations and scholarly-source cross checking, make for a very powerful interface for reading.
There is one other feature that I’m particularly fond of: Anki-style spaced-repetition. Paid users can select a section from any text and add those words to a deck, where they can later practice memorizing them.
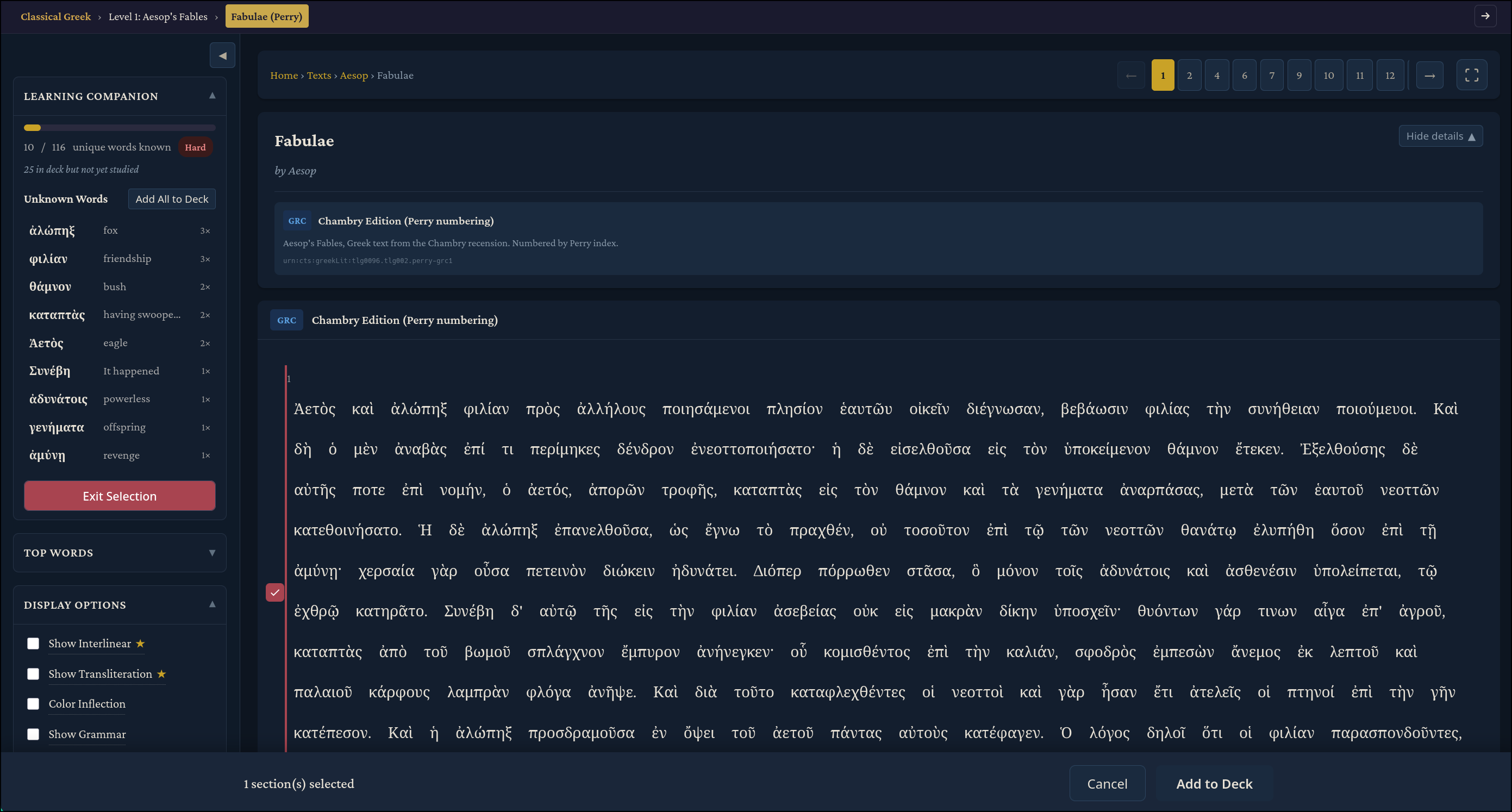
Then, clicking on the “Study” tab will take you to:
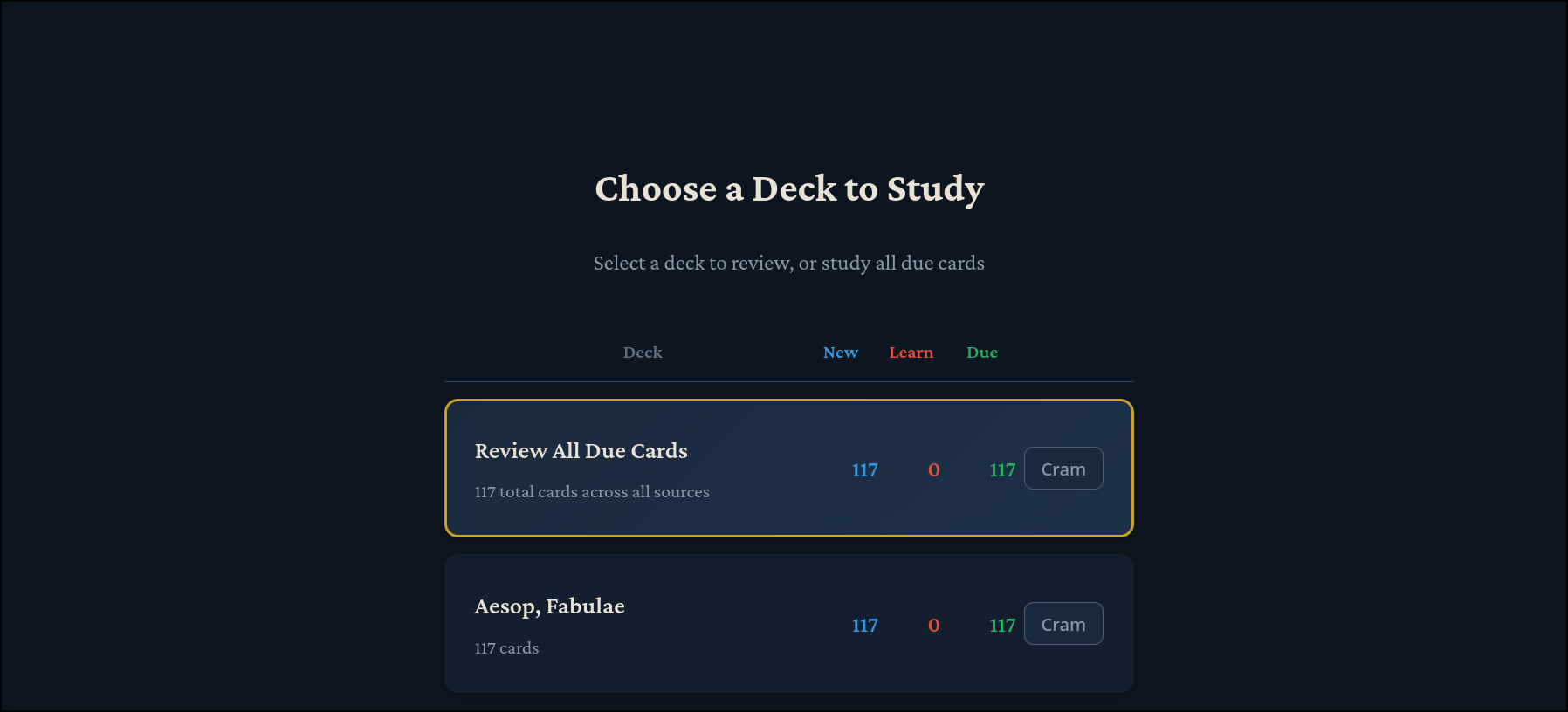
Now, you will be presented with cards like this:
Front:
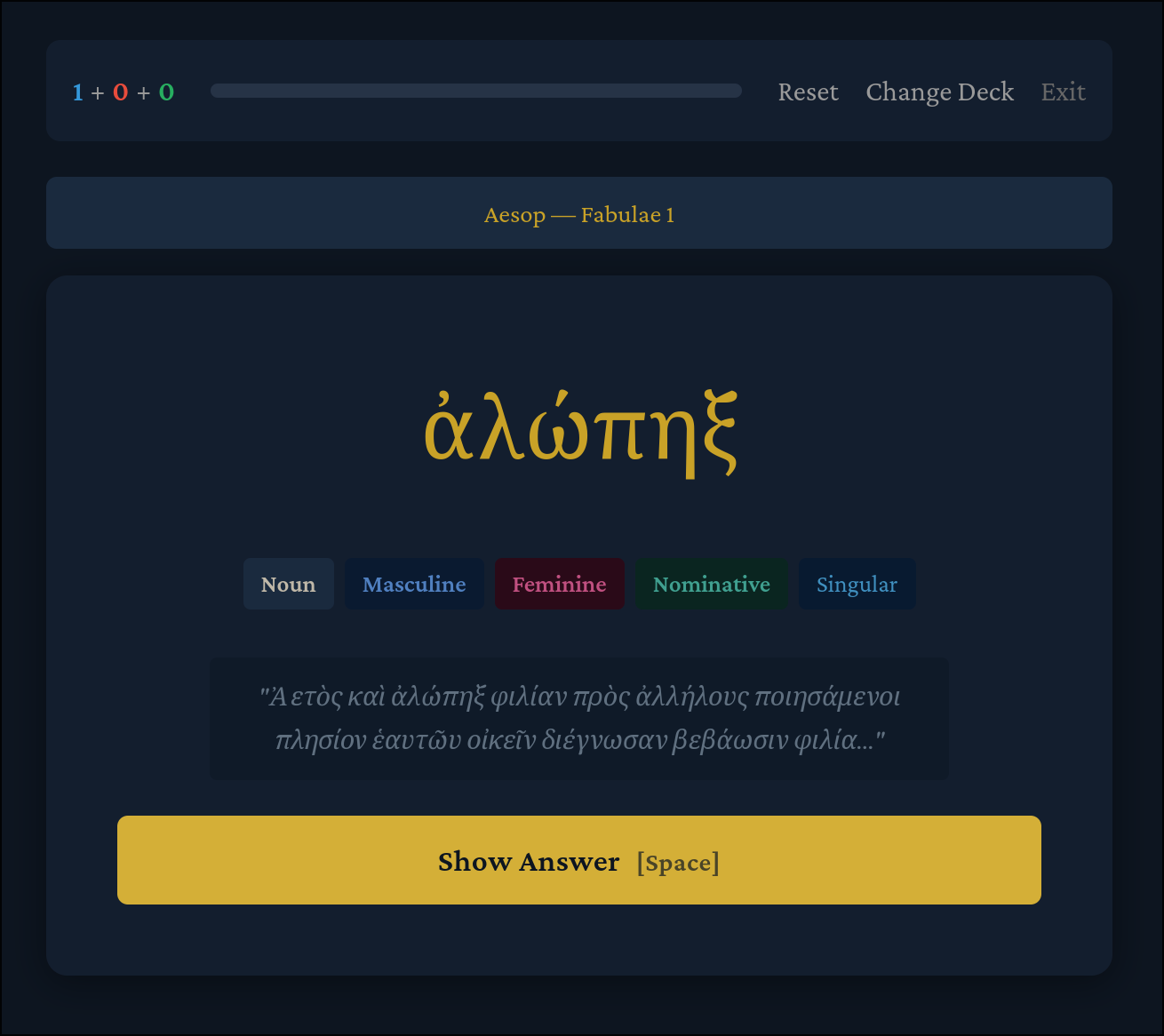
Back:
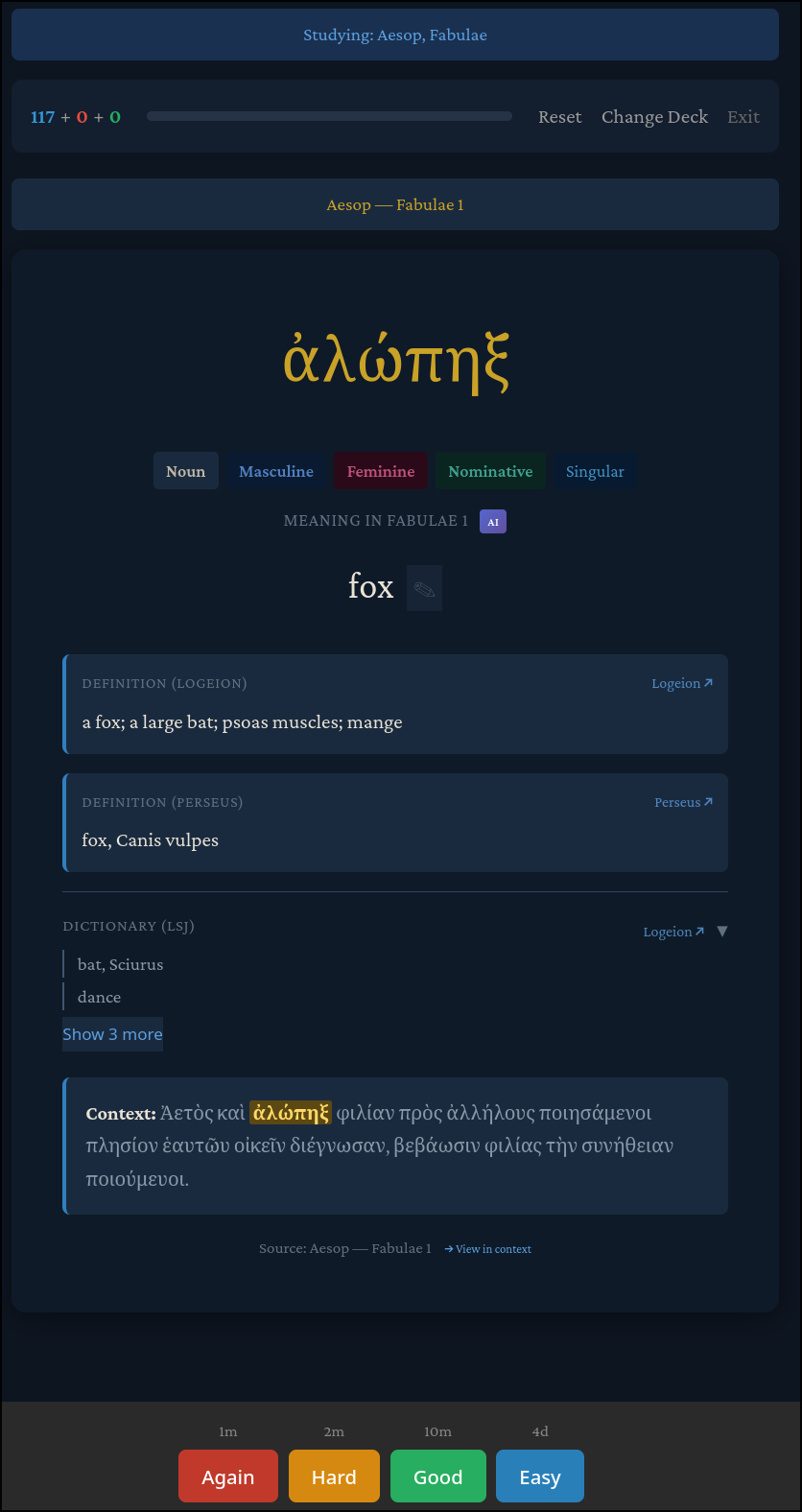
You can even click “View in context” to have it highlight occurrences of that word in the text you added it from!
Finally, we have a dashboard with a few charts to track your learning progress:
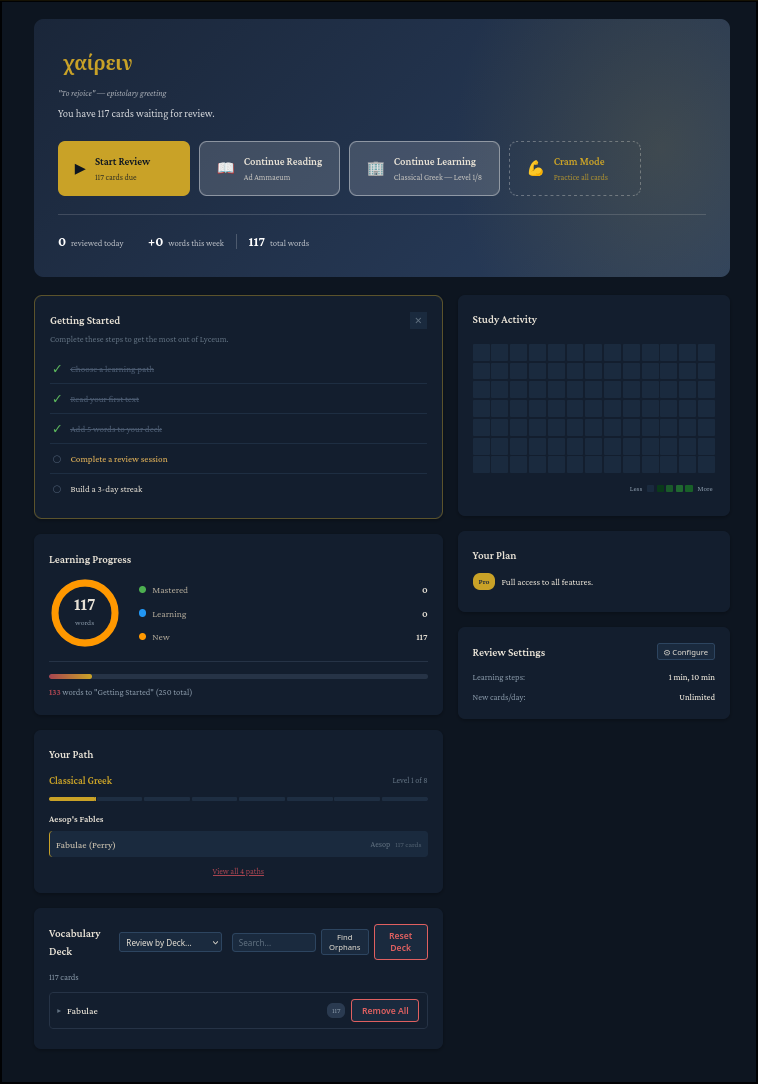
Conclusion
Lyceum is a rich modern reader for reading Ancient Greek texts with a novel combination of features to let you access the Greek authors of Antiquity in their native tongue. It is meant as a helpful, intuitive, and engaging resource to other means of learning Greek. It is under active development and new features and fixes will be added regularly.
Ultimately I’m building this because I want it to exist. I am the first customer. I now use the spaced-repetition and interlinear features every day and am learning the words from the Iliad, Odyssey and Aesop’s Fables using it. Every day I can read a little more, and I am genuinely excited by my progress. I will continue to add features I (and others) think are useful, I’m sure there are plenty of mistakes to correct and improvements to be made that I’m missing.
If you want to have a voice in Lyceum’s development or provide feedback to the project please join the Discord or send an email to support@lyceum.quest with any suggestions you have or mistakes you find.
Future goals include:
- Fix any missing or incorrect dictionary definitions, with a user-driven feedback mechanism.
- Add many more interlinear translations and transliterations especially for popular texts.
- A feedback mechanism for evaluating/correcting LLM-generated interlinear translations/transliterations.
- Full English/other language translations for a wider variety of texts (many currently only have the Greek).
- Voice/Audio enabled reads (like Legentibus) for pronunciation.
- Make texts downloadable in nice readable formats. A fun thing might even be to allow PDF generation in whatever display format options you’ve selected for offline reading.
- Some day, the above could evolve into creating books/printouts with rich morphological information per word for certain texts (for example, a book could include interlinear translations, per-word grammar information). No publisher seems to do this as of now.
Gratitude for Previous Work
Ross Scaife for laying the groundwork which led to the Scaife Viewer, which was a huge inspiration. The Vesuvius Challenge, which stirred my imagination with an excitement about rediscovering the past, the Loeb Library for their excellent books, Anki for being the only widely-adopted spaced-repetition software, Athenaze for being the book I started learning Greek with, and Legentibus for setting the gold standard for modern Latin learning and being a great resource to take inspiration from.
Data Sources:
Texts
- Perseus Digital Library Greek texts and English translations from canonical-greekLit repository. 50+ authors, 631 works, from Homer through the Church Fathers.
- Diorisis Ancient Greek Corpus: 820 pre-lemmatized XML texts with word-level morphology, POS tagging, and sentence boundaries. Used to aid in generating contextual meanings.
- First1K Greek Project: Additional Greek texts from the Open Greek and Latin project at the University of Leipzig.
- Chambry Aesopica: Chambry’s critical edition of Aesop’s Fables with Perry numbering, multiple recensions, and scholarly apparatus.
- Townsend Aesop Translation: George Fyler Townsend’s 1867 English translation of Aesop’s Fables, used for parallel reading.
Morphology & Glosses
Perseus Ancient Greek Dependency Treebank Syntactic annotations (dependency trees) and glosses for select texts including Aesop, Homer, and Attic prose. Used for word-level alignment with translations.
Diogenes: Morphological analyses for 400K+ Greek word forms. Each entry maps an inflected form to its lemma, part of speech, and full grammatical analysis (case, number, gender, tense, voice, mood, person).
Definitions
- LSJ: 116,000+ dictionary entries from the definitive Ancient Greek lexicon (9th edition, 1940). Full scholarly definitions with citations, etymology, and usage notes. The “gold standard” comprehensive Greek definitions.
Claude AI
- Content: AI-generated contextual glosses that analyze word meaning within specific passages. Used to disambiguate words with multiple meanings (e.g., “λόγος” as “word” vs “argument” vs “reason” depending on context).